Ecosystem Configuration & Governance
To balance public-benefit research with highly secure institutional deployment, Super Intelligence Lab CIC operates a dual-track ecosystem. This structure guarantees that our fundamental open-science benchmarks remain protected by a public asset lock while providing a distinct, secure deployment pathway for restricted environments.
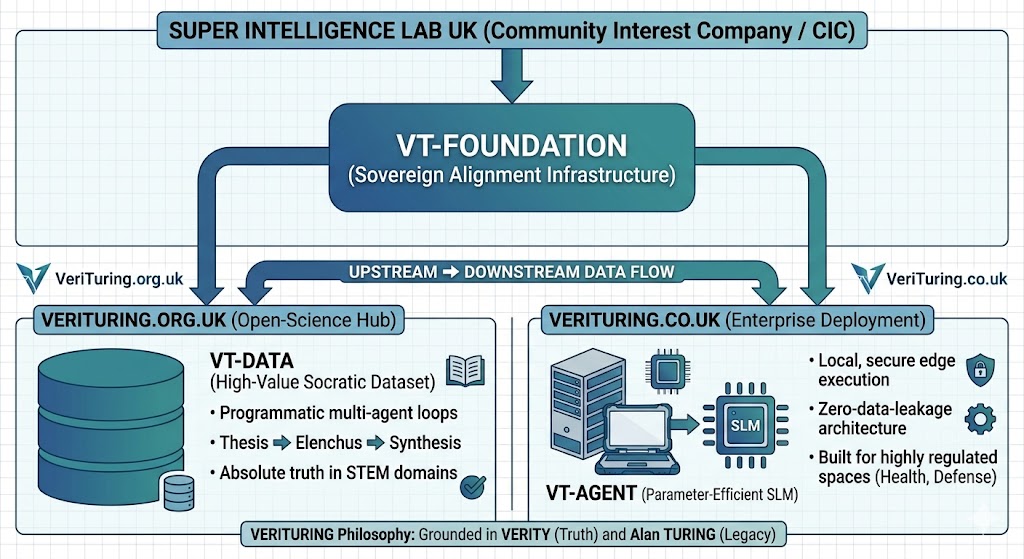
Structural Flow Breakdown
Block 1: Institutional Governance (Super Intelligence Lab CIC): The top tier establishes our regulatory framework as a UK Community Interest Company. This ensures that all upstream alignment breakthroughs and core data assets are bound by an open-science public asset lock, protecting UK data residency.
Block 2: Core Engineering Engine (VT-Foundation): Positioned as the central alignment infrastructure, this operational layer processes raw model trajectories through automated evaluation loops, acting as the industrial refinery for our downstream deployments.
Block 3: Dual-Track Ecosystem Output: The pipeline splits into two targeted endpoints:
• verituring.org.uk (The Open-Science Hub): Houses VT-Data, our programmatically curated dataset mapping multi-turn Socratic dialectical loops for open public utility.
• verituring.co.uk (The Enterprise Hub): Delivers VT-Agent, our localized Small Language Model (SLM) optimized for zero-data-leakage deployment inside highly secure, restricted institutional hardware frameworks.
Core Algorithmic Pipeline Architecture
Our post-training alignment routine entirely eliminates secondary Reward Model footprint overhead in VRAM, allowing enterprise-grade logic compression inside low-resource hardware environments through structured optimization.
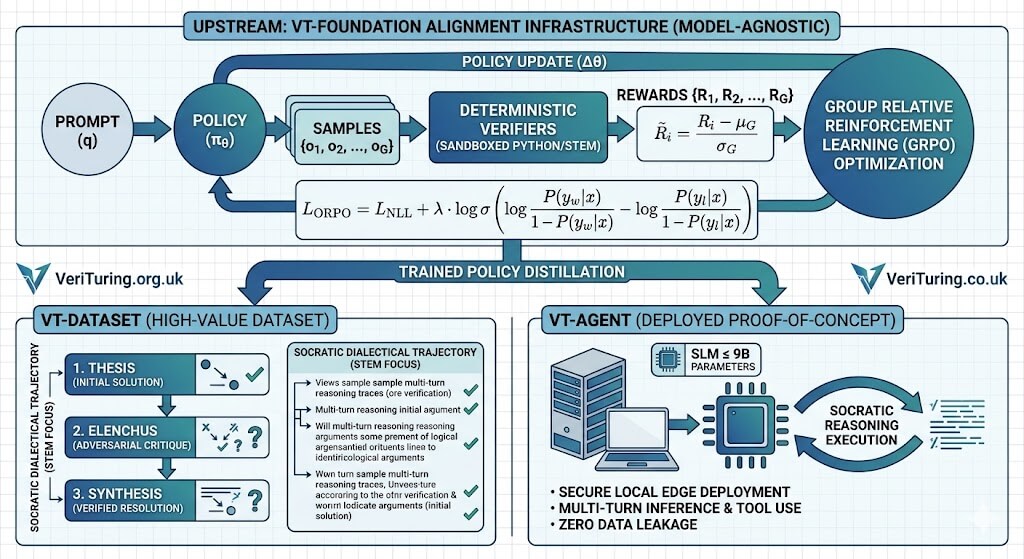
Section 1: Upstream Generation & Relative Reward Normalization (GRPO Optimization)
The core optimization pipeline bypasses traditional reinforcement learning overhead by utilizing Group Relative Policy Optimization. When a complex mathematical or logical query is introduced, the system active policy samples an isolated group of candidate responses simultaneously. Instead of routing these outputs through a massive, resource-heavy secondary Critic Model, rewards are derived using localized, deterministic rules inside sandboxed runtime checkers.
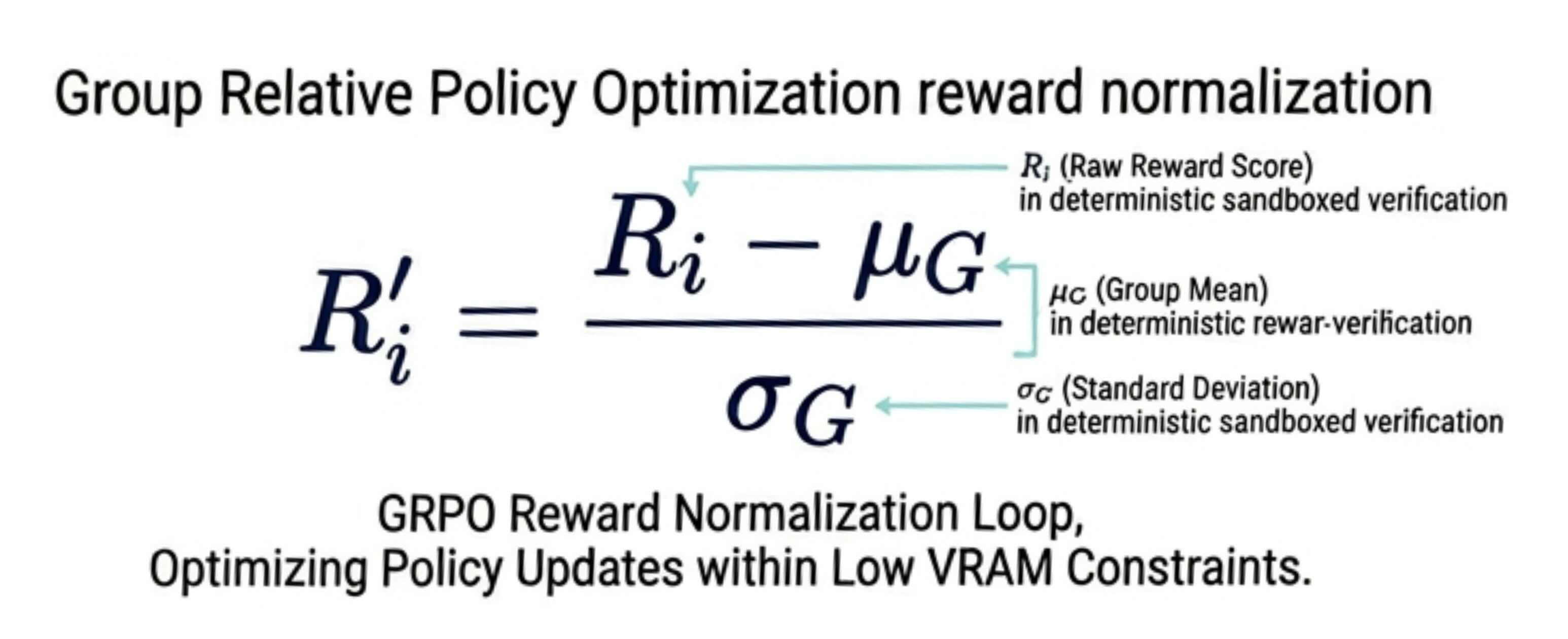
These raw scores are mathematically normalized across the specific sample group by calculating the mean and standard deviation of the batch. This approach allows the model to dynamically identify and penalize structural failures relative to successful responses in the same generation loop, drastically reducing VRAM overhead and allowing heavy logic optimization to execute entirely within localized public sector computing constraints.
Section 2: Policy Compression & Single-Step Alignment (ORPO Integration)
To ensure our compressed Small Language Models (VT-Agent ≤ 9B parameters) retain structural reasoning without suffering from model collapse, the pipeline maps updates directly using Odds Ratio Preference Optimization. Standard alignment training requires a multi-stage sequence: first running supervised fine-tuning, then training a reward model, and finally running complex reinforcement loops. This multi-step process degrades compact models and introduces vast computational overhead.

Our architecture collapses this by introducing a weak penalty directly into the negative log-likelihood loss function. By calculating the log odds ratio between verified correct reasoning paths and flawed trajectories, the algorithm penalizes hallucinatory behaviors and incorrect syntax in a single, unified training step. This forces the base model weights to adapt to safety boundaries and logical constraints simultaneously, preserving conversational nuance while maximizing mathematical verification capabilities at the absolute local network edge.
References
Explore the formal academic publications, baseline validation papers, and algorithmic blueprints supporting the VT-Foundation framework:
A. Core Alignment & Post-Training Baselines
Foundational open-science methodologies supporting our underlying model optimization and preference-tuning frameworks:
B. Autonomous Agent & Execution Frameworks
Peer-reviewed architectural logic defining how deployed local models interact with tools, construct reasoning paths, and safely query edge networks: